Lucene: Simple Recommendations
Circa 2016 (I believe)
Unfortunately, this is going to be largely vague overview of this project as I no longer have the code to refresh my memory.
The problem
While working at the Kitsap Sun, I was asked if I could get some old story archives online. Later, while looking at the analytics, I noticed that it got a surprising amount of long-tail search traffic. However, I also noticed that much of it was hit-and-run single page visits.
I figured having some related links would go a long way towards helping retain some of those visitors. There were a couple of constraints though:
Firstly, even though I had the necessary permissions to install software on the VPS, it was discouraged as that would entail having to pay the hosting provider to fix custom software installations if I left the company and it malfunctioned or needed servicing.
Additionally, that VPS was already stretched pretty thin, resource-wise.
The archive is fairly static though, so it made sense to simply pre-compute related links for the entire collection all at once, and then provide a user-interface to add them manually for the rare new entry.
Enter: Lucene
After a little bit of searching I stumbled across Lucene’s MoreLikeThis class which is exactly what I needed, and Lucene has a python binding.
The first step was to build the index. I already had all of the content as HTML files, so I used the SimpleHtmlDom library in PHP to extract the article content for each file. The useful text and some metadata was written to a series of corresponding JSON files. These JSON files would become the source Python would read to add them to the search index.
Next, after a few attempts and getting familiar enough with PyLucene to get an index constructed, I turned the importer loose on all of the JSON files. I used the original HTML file paths as the primary identifier, as that’s what the archive uses as well.
Next up was processing every file and producing yet another set of JSON files with the related links. It took some experimentation if I recall correctly to get reasonably decent results.
Finally, since it was such a large set, I actually then created a parser in PHP that turned those JSON files into a large SQL script I could feed directly to MySQL.
Analytics showed a small, but statistically significant improvement. Adding several thousand page views a month with no continuing effort.
An example of the results can be seen below:
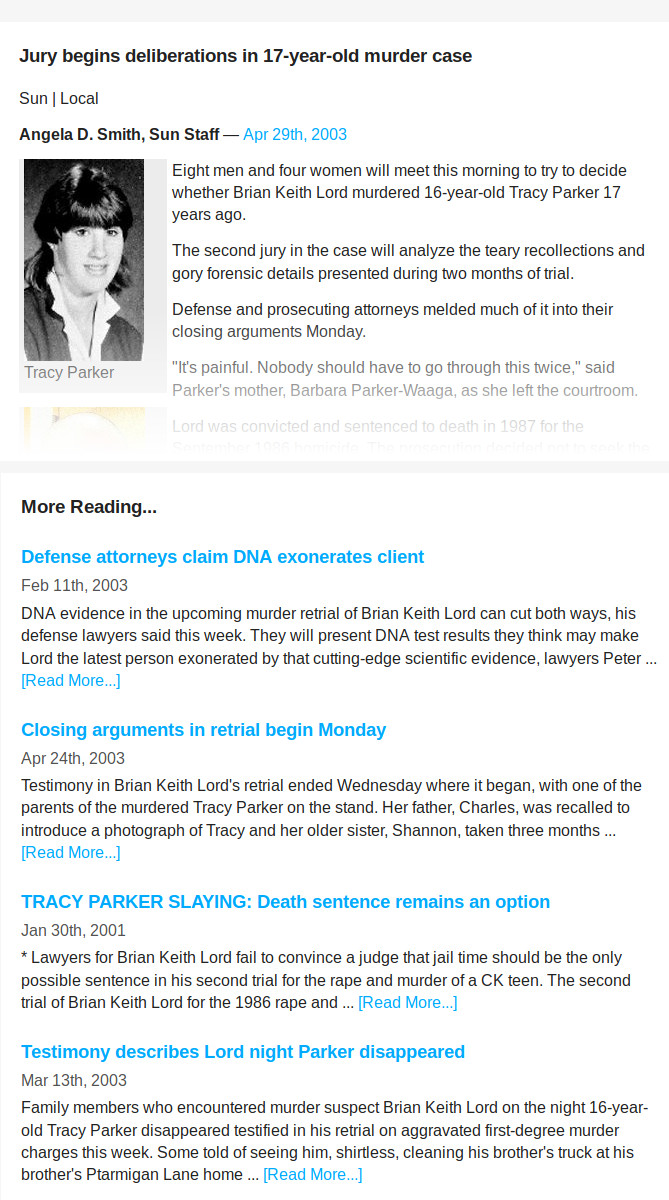
Current link to the story: Jury begins deliberations in 17-year-old murder case